Self-supervised learning survey
Survey: Self-supervised learning: Generative or Contrastive
清华唐杰团队的工作,比较完整。
自监督任务的方法共分为3类,分别为生成式(generative)、判别式(contrastive)、对抗式(generative-contrastive (adversarial)),他们的区别如下。
GENERATIVE SELF-SUPERVISED LEARNING
Auto-regressive (AR) Model
pros: The advantage of auto-regressive models is that it can model the context dependency well.
cons: However, one shortcoming of the AR model is that the token at each position can only access its context from one direction.
Flow-based Model
Auto-encoding (AE) Model
- Basic AE Model
- Context Prediction Model (CPM): The idea of the Context Prediction Model (CPM) is predicting contextual information based on inputs.
- The idea of denoising autoencoder models is that representation should be robust to the introduction of noise. The masked language model (MLM) can be regarded as a denoising because its input masks predicted tokens.
- Variational AE Model
Hybrid Generative Models
- Combining AR and AE Model.
- Combining AE and Flow-based Models
CONTRASTIVE SELF-SUPERVISED LEARNING: Contrastive learning aims at “learn to compare”.
context-instance contrast: 即对比某个样本及其它的语境
- Predict Relative Position (PRP): 直观的理解,是将原始数据的好几个部分用某种方式打乱,然后使用一个辅助的任务尝试恢复原有的数据。
例:在CV中,将某个样本,a) 分割成几个部分,然后打乱顺序,附加任务为恢复顺序;b) 做旋转,附加任务是将旋转后的样本恢复;c) 分割后完成一个拼图游戏。

- Maximize Mutual Information:直观来讲,即使用互信息来表征某个instance是否属于一个context,给定一个context-instance pair,并给定其是否属于同一个样本的标签(0:不属于,1:属于),则最小化正样本的互信息,并最大化负样本的互信息。
cons: The [132] provides empirical evidence that the success of the models mentioned above is only loosely connected to MI by showing that an upper bound MI estimator leads to ill-conditioned and lower performance representation. Instead, more should be attributed to encoder architecture and a negative sampling strategy related to metric learning.
Some examples:
(CV) maximize the MI between a local patch and its global context.
(speech) CPC maximize the association between a segment of audio and its context audio.
(NLP) maximize the mutual information between a global representation of a sentence and n-grams in it.
(Graph) Deep Graph InfoMax (DGI) [139] considers a node’s representation as the local feature and the average of randomly samples 2-hop neighbors as context.
context-context contrast: 即对比两个独立的样本
对于一个样本,首先生成他的多个副本(通过各种加噪/数据增强的方式),然后最小化这几个样本之间的相似度,并最大化这些样本与另一个独立样本的相似度。
例:在cv中,多个副本是通过裁剪、颜色转换、旋转等方式生成的。

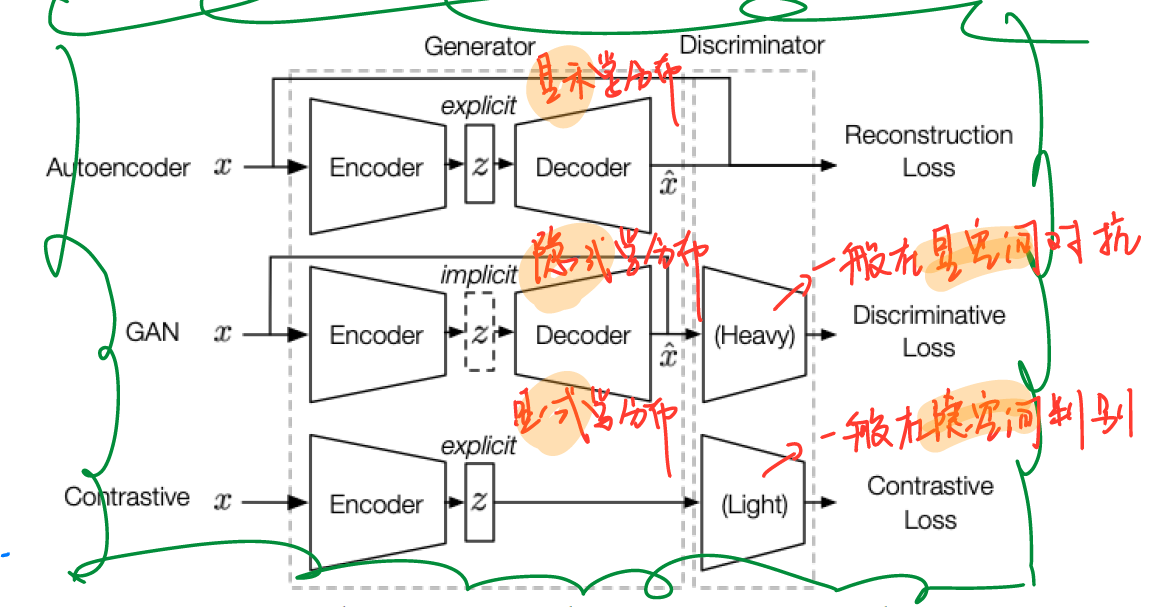
GENERATIVE-CONTRASTIVE (ADVERSARIAL) SELF-SUPERVISED LEARNING
pros: 1) A reason for the generative model’s success in self-supervised learning is its ability to fit the data distribution. 2) GANs are designed to serve for human-level understanding. 3) GANs focus on capturing the complete information of the sample.
Generate with Complete Input: 将完整的样本送入网络并进行压缩与重建,由discriminator判别重建数据与原始数据的差异。
Recover with Partial Input: 将经过处理(加噪、转换)的样本送入网络进行重建,由discriminator判别重建数据与原始完整数据的差异。从这个角度上来讲,与判别式方法非常像,但是二者学习分布的方式不同,discriminator的复杂度也不同。
